This page provides an overview of the available benchmark datasets. Each benchmark includes a detailed description of its inputs, ground truth, and evaluation metrics. You can explore the corresponding test results and access all sources on GitHub.

Bibliographic Data
Extract bibliographic data from a bibliography.

Blacklist Cards
Extract structured company information from historical index cards.
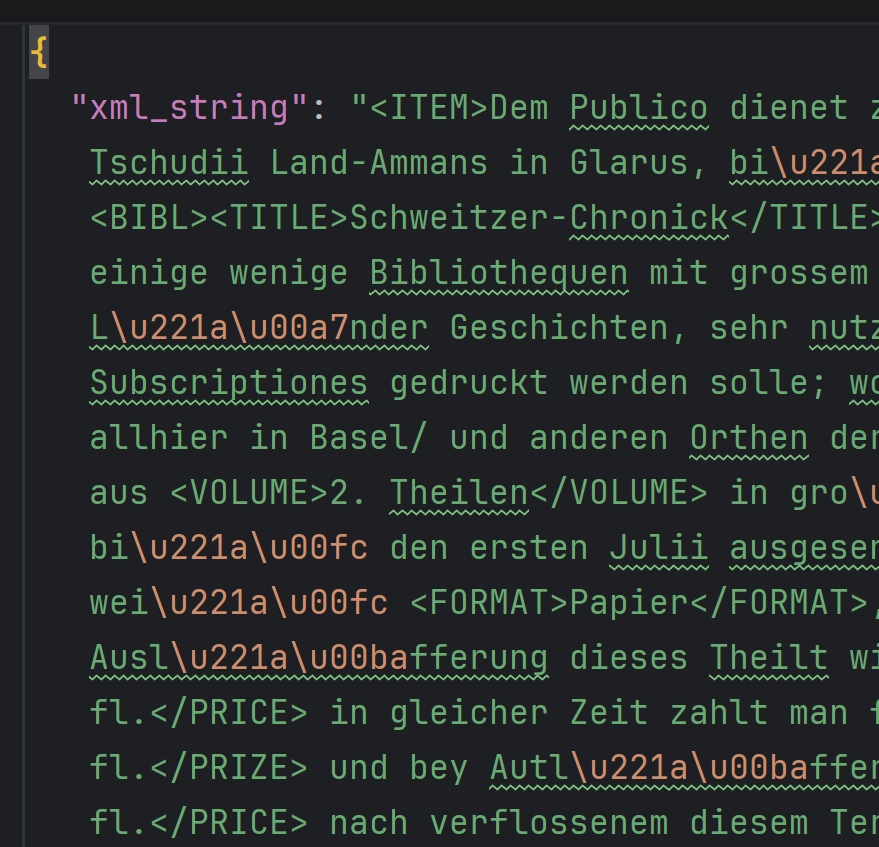
Book Advert XML files
Correct malformed XML data produced by an LLM extraction process.

Business Letters
Extract metadata from correspondence, including signature recognition.

Company Lists
Extract structured company information from various company lists.

Fraktur Adverts
Extract fraktur typeface text.
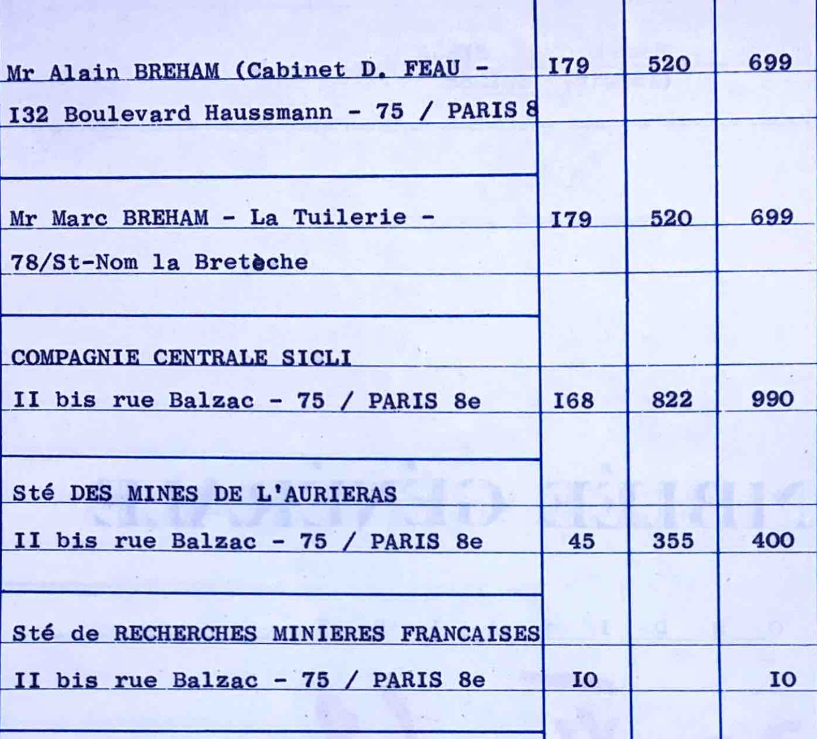
General Meeting Minutes
Extract voters and votes from business metting minutes.

Library Cards
Extract bibliographic information from index cards.

Magazine Pages
Extract bounding boxes of advertisments from magazine pages.

Medieval Manuscripts
Identify sections that contain handwritten text and extract it.
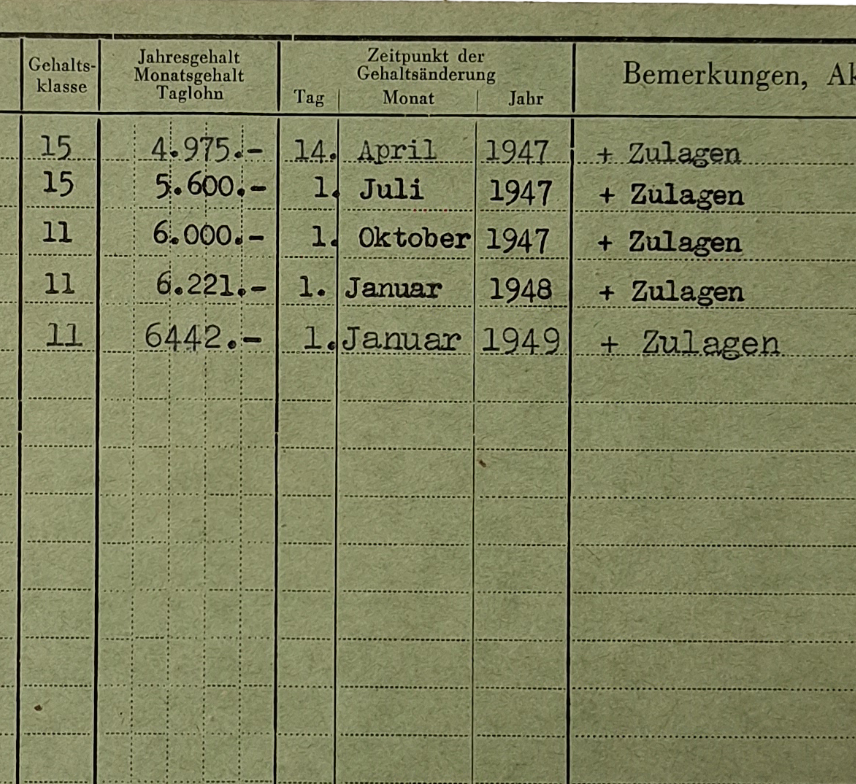
Personnel Cards
Extract and interpret structured salary information.